
분류와 정답
모델의 성능을 평가하는 요소는 모델이 내놓은 답과 실제 정답의 관계로써 정의를 내릴 수 있다.
정답이 True와 False로 나누어져있고, 분류 모델 또한 True False의 답을 내린다.

- TP : 신경망의 추측이 '참(P)'이며, 데이터의 정답 또한 '참'(T)으로 정확하게 평가한 결과
- TN : 신경망의 추측이 '거짓(N)'이며, 데이터의 정답은 '참'(T)으로 부정확하게 평가한 결과
- FP : 신경망의 추측이 '참(P)'이며, 데이터의 정답은 '거짓(F)'으로 부정확하게 평가한 결과
- FN : 신경망의 추측이 '거짓(N)'이며, 데이터의 정답 또한 '거짓(F)'으로 정확하게 평가한 결과
Precision(정밀도)
정밀도란 모델이 True라고 분류한 것 중에서 실제 True인 것의 비율입니다. 즉, 아래와 같은 식으로 표현할 수 있다.
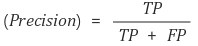
Positive 정답률, PPV(Positive Predictive Value)라고도 불린다.
날씨 예측 모델이 맑다로 예측했는데, 실제 날씨가 맑았는지를 살펴보는 지표라고 할 수 있다.
Recall(재현율)
재현율이란 실제 True인 것 중에서 모델이 True라고 예측한 것의 비율이다.

Accuracy(정확도)
위 두 지표는 모두 True를 True라고 옳게 예측한 경우에 대해서만 다루었지만, False를 False라고 예측한 경우도 옳은 경우다. 이때, 해당 경우를 고려하는 지표가 바로 정확도(Accuracy)이다.

정확도는 가장 직관적으로 모델의 성능을 나타낼 수 있는 평가 지표이다. 하지만, 여기서 고려해야하는 것이 있는데, 바로 domain의 편중(bias)이다. 만약 우리가 예측하고자 하는 한달 동안이 특정 기후에 부합하여 비오는 날이 흔치 않다고 생각해보면, 해당 data의 domain이 불균형하게되므로 맑은 것을 예측하는 성능은 높지만, 비가 오는 것을 예측하는 성능은 매우 낮을 수 밖에 없다. 따라서 이를 보완할 지표가 필요하다.
F1 score
F1 score는 Precision과 Recall의 조화평균이다.

F1 score는 데이터 label이 불균형 구조일 때, 모델의 성능을 정확하게 평가할 수 있으며, 성능을 하나의 숫자로 표현할 수 있다. 조화평균을 이용하면 산술평균을 이용하는 것보다, 큰 비중이 끼치는 bias가 줄어든다고 볼 수 있다.

ROC(Receiver Operating Characteristic) curve
여러 임계값들을 기준으로 Recall-Fallout의 변화를 시각화한 것 이다. Fallout은 실제 False인 data 중에서 모델이 True로 분류한, 그리고 Recall은 실제 True인 data 중에서 모델이 True로 분류한 비율을 나타낸 지표로써, 이 두 지표를 각각 x, y의 축으로 놓고 그려지는 그래프를 해석한다.

curve가 왼쪽 위 모서리에 가까울수록 모델의 성능이 좋다. 즉, Recall이 크고 Fall-out이 작은 모형이 좋은 모형이다.
또한 y=x 그래프보다 상단에 위치해야 어느정도 성능이 있다고 말할 수 있다.
'DL(Deep-Learning) > 개념' 카테고리의 다른 글
| train/test/validation 나누기 - splitfolders (0) | 2022.01.29 |
|---|---|
| [DL] 엔트로피 Entropy (0) | 2022.01.29 |
| 활성화 함수 activation function (0) | 2022.01.29 |
| [실습] numpy로 만드는 단층 신경망 - 회귀 문제 (0) | 2022.01.29 |
| [DL] 오차 역전파 Error Backpropagation (0) | 2022.01.28 |