![[TF Hub] 전이학습 Transfer Learning](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FxFcvZ%2FbtrsaSISQ82%2FAAAAAAAAAAAAAAAAAAAAAJtYR0--YOpf6nSAddoUO_Z8VL_4SGh8Y8PVqMNDMYGc%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1767193199%26allow_ip%3D%26allow_referer%3D%26signature%3DRTahVG3x%252FybHAfMuTaIdJcmzRJ0%253D)
전이 학습(Transfer Learning)은 미리 훈련된 모델을 다른 작업에 사용하기 위해 추가적인 학습을 시키는 것이다.
이때 훈련된 모델은 데이터에서 유의미한 특징(feature)을 뽑아내기 위한 특징 추출기(Feature Extractor)로 쓰이거나, 모델의 일부를 재학습 시키기도 한다.
가장 많이 쓰이는 컨볼루션 신경망의 전이 학습을 예를 들어보자.
미리 훈련된 컨볼루션 신경망을 불러올 때 가장 마지막의 Dense 레이어를 제외해야 한다. 이미지를 분류하는 컨볼루션 신경망에서 이 Dense 레이어는 소프트맥스 활성화 함수로 실제 분류 작업을 수행하는 레이어이다. 만약 ImageNet 데이터로 학습했다면 이 레이어의 뉴런 수는 ImageNet 문제의 이미지 분류 숫자와 같은 1,000일 것이다.
그다음 해야 할 일은 새로 분류 작업을 위한 레이블을 추가하거나, 좀 더 복잡한 분류 작업을 위해 여러 개의 Dense 레이어와 드롭아웃 레이어 등을 추가하기도 한다. 단, 마지막에 추가되는 레이어의 뉴런 수는 새로운 분류 작업의 범주 수와 같아야 한다.
그다음에는 신경망을 훈련시킨다. 이때 새로 추가된 레이어의 가중치만 훈련시킬 수도 있고, 미리 훈련된 모델의 일부 레이어를 훈련시킬 수도 있다. 이때 훈련하지 않는 레이어를 ‘얼린다(freeze)’라고 표현한다. 레이어를 얼마나 얼릴지는 새로운 작업을 위한 데이터의 양에 의해 결정한다. 새로운 작업을 위한 데이터의 양이 많을수록 기존에 훈련된 데이터와 차이가 많아져서 다시 학습할 필요가 생기기 때문에 얼리는 레이어의 양을 줄여 더 많은 레이어가 학습되게 한다.


실습하기
1. 모듈 불러오기
import tensorflow as tf
import pandas as pd
import numpy as np
import PIL.Image as Image
import matplotlib.pyplot as plt
import cv2
!nvidia-smi # 현재 코렙에서 자신이 사용하고 있는 런타임 유형을 표시
2. 데이터 불러오기
tf.keras.utils.get_file('/content/labels.csv', 'http://bit.ly/2GDxsYS')
tf.keras.utils.get_file('/content/sample_submission.csv',
'http://bit.ly/2GGnMNd')
tf.keras.utils.get_file('/content/train.zip', 'http://bit.ly/31nIyel')
tf.keras.utils.get_file('/content/test.zip', 'http://bit.ly/2GHEsnO')
여기서 사용할 새로운 데이터는 스탠퍼드 대학의 Dogs Dataset인데, 원본 데이터보다 접근이 쉬운 캐글 데이터셋을 사용하고자 한다.
케글에서 데이터를 불러오기 위해 tf.keras의 get_file()를 활용하여 각 레이블, 제출 파일, 학습 및 테스트 파일(zip)을 불러와 준다.
케글에서 데이터를 불러왔기에 제출 파일이 포함되어 있는 것을 확인할 수 있다.
2.1 zip을 풀어주기 위한 과정 unzip을 수행
!unzip train.zip
!unzip test.zip
2.2 정답 라벨을 담고 있는 csv 파일의 내용 살펴보기
import pandas as pd
label_text = pd.read_csv('labels.csv')
print(label_text.head())

id 컬럼에 있는 값은 각 사진 파일의 이름이다. breed 컬럼에는 각 사진이 어느 견종인지 분류돼 있다.
2.2.1 분류를 위한 견종의 수 확인하기
label_text['breed'].nunique()
# 120
# 실제로 어떤 사진들로 구성돼 있는지 이미지와 라벨을 함께 출력하며 확인
plt.figure(figsize=(12, 12))
for i in range(16):
#loc[i번째 행,'id' 라는 열]
image_id = label_text.loc[i, 'id']
plt.subplot(4, 4, i + 1)
#절대경로 설정을 활용하여 사진 출력
plt.imshow(plt.imread('/content/train/' + image_id + '.jpg'))
#사진과 함께 번호(i) + 제목 ( loc[i,'breed'] ) 출력
plt.title(str(i) + ', ' + label_text.loc[i, 'breed'])
# 축 정보 표기 x
plt.axis('off')
plt.show()

전이 학습을 사용하기 전에 먼저 MobileNet V2의 모든 레이어의 가중치를 초기화한 상태에서 학습을 시켜보자.
레이어 구조는 같지만 ImageNet의 데이터로 미리 훈련된 이미지 분류에 대한 지식은 전혀 없는 상태에서
학습시켜보는 것이다.
3. 신경망의 가중치를 초기화
from tensorflow.keras.applications import MobileNetV2
mobile_v2 = MobileNetV2()
#사전 훈련된 신경망에 layers로 접근하여 마지막 dense 층 제외한 모든 가중치를 선택
for layer in mobile_v2.layers[:-1]:
#모든 레이어들을 'trainable(훈련가능)' 여부 True로 전환
layer.trainable = True
#마지막 레이어 제외한 모든 레이어에 접근
for layer in mobile_v2.layers[:-1]:
#레이어에 커널(가중치)이 존재하는 경우 확인
if 'kernel' in layer.__dict__:
#가중치를 획득하여 가중치의 모양(shape)을 kernel_shape에 저장
kernel_shape = np.array(layer.get_weights()).shape
#레이어의 가중치를 설정한다. '표준정규분포'.
layer.set_weights(tf.random.normal(kernel_shape, 0, 1))
4. 이미지에 대한 전처리를 수행
import cv2
train_X = [] # 학습데이터 저장 리스트 생성
len(label_text) # 모든 이미지의 수 확인
for i in range(len(label_text)): # 모든 이미지만큼 반복 수행
#이미지 읽어들이기
img = cv2.imread('/content/train/' + label_text['id'][i] + '.jpg')
img = cv2.resize(img, dsize=(224, 224)) # 이미지 크기 통일
img = img / 255.0 # 이미지 크기 최소-최대 정규화
#(이미지 크기 축소)
train_X.append(img) # 빈 리스트에 학습 데이터 생성
train_X = np.array(train_X)
# 학습 데이터의 차원 및 크기 확인
print(train_X.shape) # (10222, 224, 224, 3)
print(train_X.size * train_X.itemsize, ' bytes') # 12309577728 bytes
5. 단순 문자열로 구축되어 있는 label 데이터를 숫자로 변환
#'breed'라는 속성값 안에 포함된 데이터 중 '유일 값'을 찾아 '리스트'로 전환하여 저장
unique_Y = label_text['breed'].unique().tolist()
# 품종을 하나씩 반복하여 꺼내, 앞서 unique_Y에서 설정한 위치로 반환해 준다.
train_Y = [unique_Y.index(breed) for breed in label_text['breed']]
#array 로 전환
train_Y = np.array(train_Y)
print(train_Y[:10]) # [0 1 2 3 4 5 5 6 7 8]
print(train_Y[-10:]) # [34 87 91 63 48 6 93 63 77 92]
6. 전이 학습을 위한 신경망
# 마지막 Dense 레이어를 제거하기 위해 [-2].output 그리고 밖으로 빼내준다.
x = mobile_v2.layers[-2].output
# 예측을 위한 레이어 재정의 ( 예측 범주 1000개(이전 레이어의 유닛수) -> 120개 )
predictions = tf.keras.layers.Dense(120, activation='softmax')(x) # x모델이랑 연결되는 모델임을 말한다.
#'입출력 구조' 재정의
model = tf.keras.Model(inputs=mobile_v2.input, outputs=predictions)
model.summary()
이번에는 랜덤한 가중치를 사용하기 때문에 가져오는 지식이 없어서 전이 학습이라고 하기는 어렵지만 바로 다음에 미리 훈련된 가중치를 사용해 학습시킬 것이다.
첫 번째 줄에서는 MobileNetV2에서 마지막 Dense레이어를 제외하기 위해 뒤에서 두 번째 레이어를 지정해서 그 레이어의 output을 x라는 변수에 저장했다. 그다음에는 Dogs Dataset의 분류를 위해 120개의 뉴런을 가진 Dense 레이어를 새롭게 만들었다.
지금까지는 tf.keras.Sequential 모델만을 사용하였다. 여기서는 레이어가 함수처럼 밖으로 나오고 x라는 인수를 받는다. 그 계산은 predictions 라는 변수에 저장된다.

레이어를 함수처럼 사용하는 구문을 케라스의 함수 API라고 한다. 입력부터 출력까지 일직선의 구조라면 Sequential 모델을 사용해도 되지만, 그렇지 않은 경우에는 함수형 모델을 사용해 모델의 입력, 출력 구조를 정의해야 한다.
함수형 모델을 정의하기 위해서는 연결에 필요한 모든 레이어를 준비한 다음에 tf.keras.Model()의 인수인 inputs, outputs에 각각 입력과 출력에 해당하는 부분을 넣으면 tf.keras가 그 사이의 연결을 알아서 찾아서 모델을 만든다. 물론 입력과 출력 사이에 연결이 되지 않을 경우에는 에러가 출력된다.
model.compile(optimizer='sgd',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])

훈련 가능한 가중치의 수(Trainable params)가 총 240만 개 중 237만 개로 대부분인 것을 확인할 수 있다.
7. 학습
fit()를 활용하여 학습을 진행하여 주고, callbacks를 통해 조기 중단 기법을 적용한다.
history = model.fit(train_X,
train_Y,
epochs=10,
validation_split=0.25,
batch_size=32,
callbacks=[
tf.keras.callbacks.EarlyStopping(patience=5,
monitor='val_loss')
])

수치를 확인해 보면 학습에 대한 성능 향상이 원활하게 되지 않고 있다는 것을 알 수 있다.
미리 학습된 가중치를 전부 초기화 하였기 때문에 어찌보면 당연할 결과라 할 수 있다.
8. 시각화
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], 'b-', label='loss')
plt.plot(history.history['val_loss'], 'r--', label='val_loss')
plt.xlabel('Epoch')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], 'g-', label='accuracy')
plt.plot(history.history['val_accuracy'], 'k--', label='val_accuracy')
plt.xlabel('Epoch')
plt.ylim(0, 0.1)
plt.legend()
plt.show()

MobileNetV2의 일부 계층만의 가중치를 초기화하여 학습
from tensorflow.keras.applications import MobileNetV2
mobilev2 = MobileNetV2()
x = mobilev2.layers[-2].output
predictions = tf.keras.layers.Dense(120, activation='softmax')(x)
model = tf.keras.Model(inputs=mobilev2.input, outputs=predictions)
처음부터 마지막 20개를 제외한 레이어는 얼려주고, 나머지 20개는 학습 가능한 상태로두었다.
for layer in model.layers[:-20]:
layer.trainable = False
for layer in model.layers[-20:]:
layer.trainable = True
model.summary()

학습 가능한 파라미터와 그렇지 못한 파라미터의 수가 이전과 달라진 것을 확인할 수 있다.
model.compile(optimizer='sgd',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(train_X,
train_Y,
epochs=10,
validation_split=0.25,
batch_size=32)
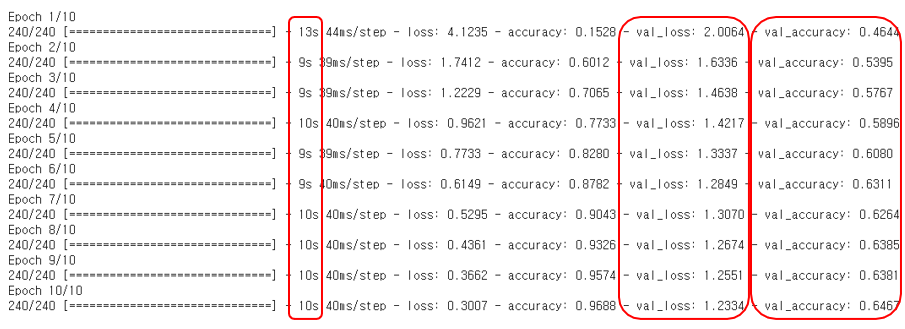
이전과는 달리 확실히 학습이 진행되고 있다는 것을 알 수 있다.
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], 'b-', label='loss')
plt.plot(history.history['val_loss'], 'r--', label='val_loss')
plt.xlabel('Epoch')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], 'g-', label='accuracy')
plt.plot(history.history['val_accuracy'], 'k--', label='val_accuracy')
plt.xlabel('Epoch')
plt.legend()
plt.show()

'DL(Deep-Learning) > Tensorflow' 카테고리의 다른 글
| [Error] tf.keras.models.load_model 에러 해결방법 (0) | 2022.01.30 |
|---|---|
| [TF Hub] 사전 훈련된 모델 사용하기 (0) | 2022.01.29 |
| [Keras] callback 함수 - ReduceLROnPlateau (0) | 2022.01.25 |
| [Keras] callback 함수 - EarlyStopping (0) | 2022.01.25 |
| [Mac M1] Tensorflow 설치 방법 (0) | 2022.01.24 |